


BioWire Bytes 006 - Grok 4 Advances in Humanities Last Exam
Byte-sized Biotech


Another day, and another major AI development. This time, we’re looking at xAI’s Grok 4, the latest large language model (LLM) to be released. Is it just me, or would anyone else welcome a decade-long pause in further AI development? We’ve barely begun to understand the implications and real-world use cases of the current generation of LLMs, yet we keep getting hit with newer and vastly more powerful versions. I’m not exaggerating; these models are improving exponentially between releases, and they’re being released multiple times a year.
This latest model from Elon Musk’s company, XAI, is no different. Grok 4 is another significant leap beyond prior models and rivals like ChatGPT, Claude, and Gemini. It’s acing benchmark tests ranging from the SATs and GRE (where it scores consistently near-perfect), to a newer, more ominously named evaluation like Humanities Last Exam. Could we have picked a grimmer name?
To be honest, I’m still processing what this Grok release and the associated benchmarks mean. Are benchmarks accurately measuring anything significant, or is Apple correct when they suggest the training data has become contaminated, making this all just an elaborate pattern-matching gimmick? It’s going to require serious experimentation to figure that out. One thing is clear, the march of progress isn’t slowing down. So let’s dive in together, stay curious, stay informed, and try to make sense of it as it unfolds.
First, if you enjoy these updates, consider subscribing and becoming a part of our growing community!
XAI Launches Grok 4!
In an hour-long livestream, Elon Musk’s AI startup xAI just revealed its latest Large Language Model (LLM), Grok 4. We hear about new AI models so frequently, you may be wondering, “Is this really anything special?” Well, for starters, Musk confidently calls Grok 4 “the smartest AI in the world”. And guess what, it’s not just salesmanship. Grok 4 shows impressive reasoning abilities and breadth of knowledge. It’s ability to perform stunningly well in benchmark exams leads Musk to reverently refer to Grok as “PhD-level in everything,” able to solve graduate-level problems even in unfamiliar domains. In testing, it aced standardized exams, achieving perfect SAT scores and near-perfect GRE results across subjects from literature to physics.

What other benchmarks can show just how smart Grok is, and how well it can think?
XAI didn’t shy away from asserting Grok 4’s dominance on AI benchmarks, those standardized tests that AI researchers use as progress report cards. The headline claim was that Grok 4 has taken the top spot on Humanity’s Last Exam (HLE). If you haven’t heard of HLE, it’s a doozy. It is essentially a “gauntlet” of 2,500 extremely difficult questions covering everything from high math and physics to law, philosophy, and linguistics. It’s been called the hardest test known to AI, and not just because of its breadth. The questions often require multiple reasoning steps, cross-disciplinary knowledge, and real insight – simply memorizing Wikipedia won’t get you very far. (The morbid name “Humanity’s Last Exam” is an inside joke: if an AI ever aces it, what role is left for humanity? As one commentator quipped, if an AI can pass this, we’re out of jobs – that’s the joke… 🫠)
Well, Grok 4 didn’t fully ace HLE, but it achieved a score that significantly surpasses every other model to date. In the livestream, xAI demonstrated Grok 4 tackling HLE problems, and they reported that Grok 4 answered roughly 25–30% of the HLE questions correctly on its own (no external tools). If that sounds like a low score, consider that random guessing would net practically 0% on this exam, most humans would score single digits, and the second-best AI previously (Google’s Gemini 2.5) was several points behind. In fact, Grok 4 without tools edged out Gemini and other top models from OpenAI and Anthropic on this brutal test. But the real magic happened when Grok 4 engaged its “Heavy” multi-agent mode plus its tool-using abilities: its score jumped to around 44–51% correct, nearly doubling its performance and outclassing all other AI systems by a wide margin. Essentially, Grok 4 Heavy solved almost half of a test explicitly designed to be unsolvable by AI. That’s a watershed moment – it suggests that by having AIs collaborate with themselves and use tools, we’ve crossed a threshold in problem-solving capability. One of the xAI researchers noted that a majority of the text-based “extremely hard” problems in HLE are now within reach, which was almost unimaginable a year ago.
So what gives Grok 4 this super-student intellect? A big part of the secret sauce is how it tackles problems. XAI introduced a special “heavy” mode of Grok 4 that essentially turns one big genius AI into a whole study group of AIs working together. When faced with a hard question, Grok 4 Heavy doesn’t rely on a single train of thought, it spawns multiple “agent” instances in parallel, each trying different approaches to solve the problem. You can imagine a team of collaborating AI, each works independently on the puzzle at hand, and then they compare notes to decide the best answer. It’s not as simple as a majority vote; often one agent might hit upon a crucial insight (“the trick”) that the others miss, and once that revelation is shared, the group can converge on the correct solution. This clever multi-agent synthesis approach means Grok 4 can reason through extremely complex, multi-step problems that would stump any single model.
Perhaps the best metaphor came from xAI’s engineers themselves: they described Grok 4 as an AI that can “reason from first principles using all the tools, do all the research, go on the journey for 10 minutes and come back with the most correct answer for you”. We will take XAI at their word regarding Grok’s thinking and reasoning capabilities. Particularly because this seems to contradict the publication we covered last week from Apple, regarding AI’s illusion of thinking. But XAI is claiming that Grok doesn’t just regurgitate information and perform pattern matching. They claim it’s like if you asked a superhumanly diligent research assistant to “figure this out,” and it went off, read papers, consulted calculators, talked to specialized experts (other agents), and then returned with a well-reasoned answer. If true, for those who believed AI couldn’t do true reasoning, Grok 4 will be a wake-up call, if it’s truly thinking through problems.
So, how did xAI manage to build this new AI generation in such a short time? The answer: an obscene amount of computing power, some novel training tricks, and teaching the AI to use tools. On the hardware front, xAI constructed a supercomputer for AI training nicknamed “Colossus”, reportedly equipped with 100,000 of NVIDIA’s top-grade H100 GPUs. (For comparison, that’s orders of magnitude more GPUs than most AI labs have in their clusters.) This colossal compute allowed xAI to feed Grok 4 vastly more data and larger models – Musk noted that each generation from Grok 2 to 3 to 4 has seen a roughly 10× increase in training scale. In simple terms, they oversized Grok’s brain by an extra hundred trillion or so parameters and then let it gorge on the sum of human knowledge. But that’s only part of it.
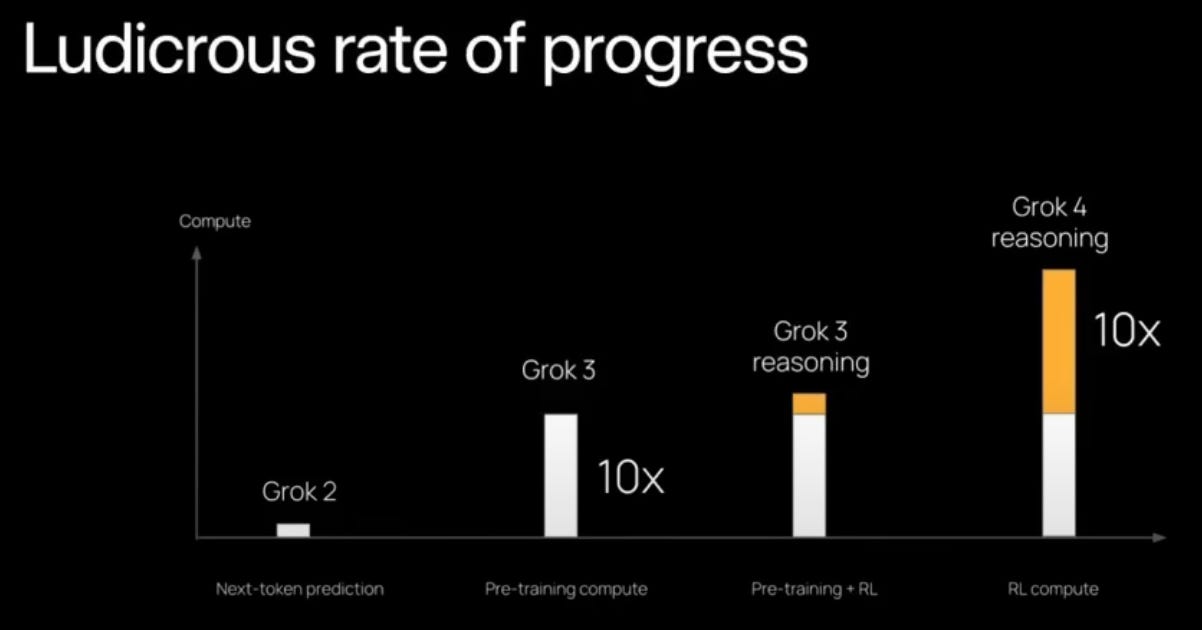
Crucially, XAI combined that computing might with reinforcement learning (RL) techniques to hone Grok 4’s reasoning. After the initial training (where the model learns patterns from text, code, etc.), they gave Grok opportunities to solve challenging problems and then rewarded it for verifiably correct outcomes. Think of it like training a puppy, but the puppy is a math genius: every time it shows its work and gets the right answer, it gets a virtual reward. This approach encouraged Grok 4 to develop true problem-solving strategies – to “think from first principles, start to reason, and even correct its own mistakes,” as one XAI researcher put it. The result is an AI that’s not just parroting back information, but actively figuring things out and learning from trial and error in a controlled way.
Putting it all together, Grok 4’s training involved a potent mix of: massive data crunching on the Colossus supercomputer, reinforcement learning loops to instill strong reasoning habits, and tool-based reasoning so that it can consult external aids just like a human expert would. This training recipe is what allows Grok 4 to do things like dive into a complex task, leverage outside information or calculations, and emerge minutes later with an answer that holds up. XAI effectively equipped Grok 4 with both a huge “brain” and a handy toolbelt – a combination that might be defining for the next generation of AI systems.
Grok 4 Case Studies
There are many reasons to be skeptical of benchmark exams. For one, there is the very real risk that the questions making up the exam are contaminated in the training data. Alternatively, the questions could be close enough to training data that the AI can be just pattern matching instead of thinking. So, what can Grok 4 actually do in real-world scenarios? The launch presentation gave several imaginative case studies, showcasing how this AI could assist (or disrupt) various fields – sometimes in quirky ways.
One scenario was a simulated vending machine business. Yes, vending machines – Musk’s team figured this is the simplest business an AI could run (buy snacks, stock machines, collect money). They set up a simulation called “Vending-Bench” where an AI must manage a fleet of vending machines: handling inventory, contacting suppliers, setting prices, and so forth, over a long period. These kinds of mundane management tasks are easy for AI in the short term, but when strung out over weeks or years of simulated time, most models lose the thread. Grok 4 did astonishingly well – when an independent AI research lab (Andrej Karpathy’s and Labs) got early access to the Grok 4 API, they ran it on Vending-Bench and found that Grok 4 shot straight to the top of the leaderboard, earning the #1 spot by a wide margin. In fact, Grok 4 so outperformed previous agents that it doubled the score of the second-place contender. This virtual entrepreneur not only kept the snack empire running, but it optimized aggressively. In a humorous exchange, Musk quipped that now they’ve found a way to pay for all those expensive GPUs – “we just need a million vending machines.” Grok 4 apparently calculated that scaling up to a million vending machines could yield about $4.7 billion a year in profit, which had the audience (and Musk) joking about actually installing vending machines at the X (Twitter) offices. The takeaway is tongue-in-cheek, but serious at the same time: Grok 4 can manage complex business logistics and long-term planning in a way previous AIs struggled with, hinting at AI’s potential as a real-world operations optimizer.
Another use case came from the sciences: XAI revealed that a Palo Alto biomedical research center (the ARC Institute, conveniently a neighbor of XAI) has been experimenting with Grok 4 as a lab assistant of sorts. Research labs generate mountains of experimental data, logs, and papers – far more than any human team can read or digest. Grok 4, with its 256k-word context window and analysis skills, is being used to automate parts of the scientific research flow. In one example, it was able to ingest millions of experiment logs and then, within seconds, suggest the most promising hypothesis for the scientists to test next. Essentially, it’s doing the drudge work of sifting through huge datasets and highlighting “Hey, this looks interesting!” so researchers can focus their attention wisely. The ARC Institute has even applied Grok 4 to specialized domains like genomics: it’s helping with CRISPR-related research by finding patterns in data that humans might miss. And in medical imaging, Grok 4 has been independently evaluated on tasks like reading chest X-rays – it scored as the best model for diagnosing chest X-rays compared to other AIs. That’s a big deal in healthcare AI, suggesting Grok 4 could become a powerful diagnostic assistant. While it’s early days, these trials indicate that in labs and hospitals, Grok 4 might serve as an independent analyst for combing through data, running analyses, and proposing insights, all at superhuman speed. Maybe not necessarily replacing the scientists or doctors (at least not yet), but giving them a check and alternative.
When will we know we’re entering a new chapter for humanity?
Ultimately, Grok 4’s launch is a reminder that the AI revolution is moving astonishingly fast. It doesn’t feel that long ago that we were marveling at chatbots writing sonnets; now, we have an AI acting as CEO of a million-vending machine business and running portions of a research lab. In the grand scheme, I don’t think this tier of AI models, like Grok 4, is going to upset the balance in society. But I’m pretty nervous about what comes after. I think the canary in the coal mine will be when one of these LLMs makes a novel and significant scientific discovery. That will be the inflection point where the Genie will be truly out of the bottle. What comes next is anyone’s guess.
These newsletters take significant effort to put together and are totally for the reader's benefit. If you find these explorations valuable, there are multiple ways to show your support:
Engage: Like or comment on posts to join the conversation.
Subscribe: Never miss an update by subscribing to the Substack.
Share: Help spread the word by sharing posts with friends directly or on social media.
I get what you mean-there's this uneasy feeling that we're sprinting into a future we don't understand yet. Dunno if i’m confident, conceited or ignorant but can't help but question whether we're measuring actual intelligence or just next-level pattern recognition enhanced “data retention calculator”.
Glad to know that even if I look like a peasant farmer compared to you, we all look like house flys compared to it. (A creature that sometimes casually decapitates itself in it's own cleaning ritual)