
BioWire Bytes 002 - ChatBots Aren't Actually Thinking
Byte-sized Biotech

The Illusion of Thinking in AI Reasoning Models

Standard large language models (LLMs) such as ChatGPT, Grok, Claude, and Gemini have become ubiquitously used tools for performing basic tasks and functions. They often succeed by learning complex patterns from data, but they struggle with tasks requiring genuine step-by-step logical reasoning. Studies have shown that even state-of-the-art LLMs do not exhibit true formal reasoning, as they are primarily relying on pattern matching, and their performance can break down if a problem is rephrased or contains irrelevant details. In other words, simply scaling up model size or training data tends to produce better pattern matchers, not fundamental reasoners.
These shortcomings motivated the new development of reasoning-augmented LLMs that incorporate explicit “thinking” processes, or at least attempt to do so. The techniques like ‘chain-of-thought’ prompting and ‘self-reflection’ enable these Large Reasoning Models (LRMs) to simulate step-by-step problem solving, with the aim of handling complex logic puzzles better than standard LLMs. For example, Anthropic’s Claude 3.7 has a special thinking mode (Claude 3.7 Sonnet Thinking) and ChatGPT’s o4 mini is a reasoning-optimized model – both are designed to generate and utilize intermediate reasoning tokens, unlike their non-thinking counterparts. These reasoning models expend additional computation on an internal thought process in hopes of improving accuracy on challenging tasks that stump normal LLMs.
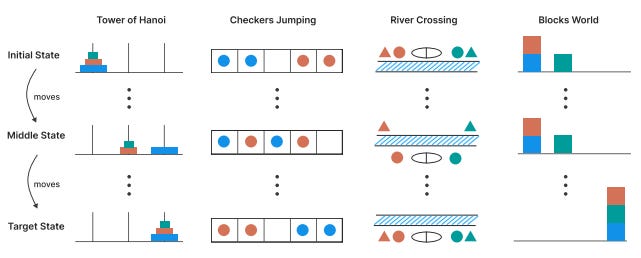
To rigorously test whether reasoning-augmented LLMs truly overcome the limitations of traditional LLMs, researchers designed new controllable puzzle environments as evaluation benchmarks. In a recent Apple study, four classic puzzle domains were used: Tower of Hanoi, Checkers Jumping, River Crossing, and Blocks World. Crucially, each puzzle type allowed precise control of problem complexity (e.g. increasing the number of disks in Tower of Hanoi or the number of pieces in River Crossing) without changing the fundamental logic of the task (Shojaee et al., 2025). This setup ensured a fair comparison between reasoning models and non-reasoning models across varying difficulty levels. By gradually scaling up puzzle complexity, the researchers could observe how each model’s performance and behavior changed, shedding light on whether the chain-of-thought reasoning truly provided an advantage over standard LLM outputs.
The study demonstrates three distinct performance regimes based on problem complexity. At lower complexity levels, standard, non-thinking models surprisingly outperform LRMs, achieving better accuracy and efficiency. As problems grow moderately complex, the additional "thinking" in LRMs begins to show clear advantages, successfully solving tasks that standard models cannot handle. Yet, when complexity rises even further, both models face a dramatic performance collapse, reaching zero accuracy at higher difficulty levels.
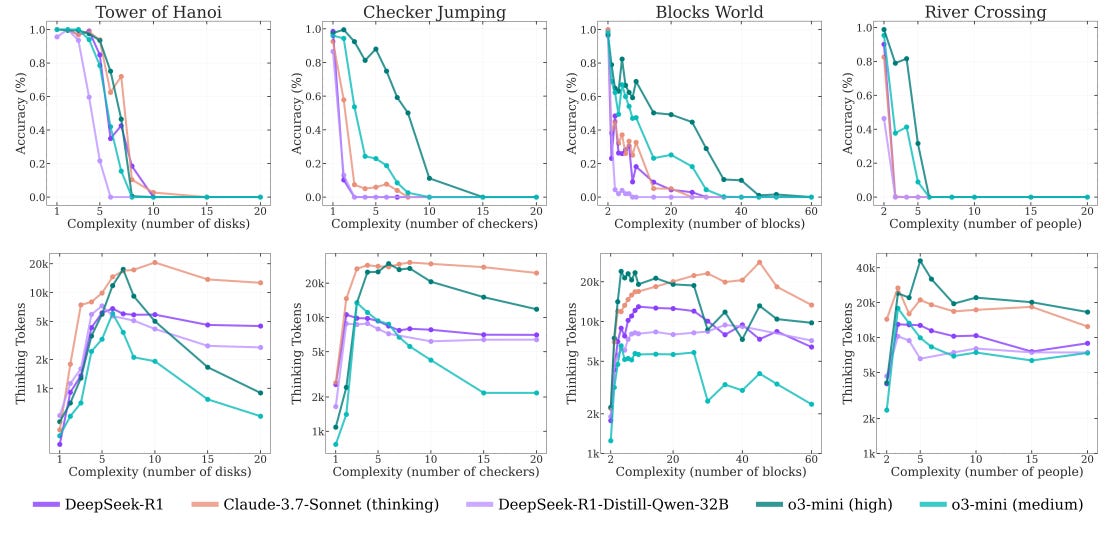
Remarkably, LRMs also exhibit counterintuitive scaling behavior: as problems approach their complexity threshold, these models actually decrease their reasoning effort, using fewer inference tokens despite having ample available resources. This puzzling behavior suggests fundamental limitations in current reasoning methods, challenging prevailing assumptions about the nature and capabilities of these sophisticated AI systems.
Overall, the investigation shows that while reasoning-augmented LLMs do provide improvements on mid-level reasoning problems, they are not universally better than simpler models. These specialized models fail to develop truly general problem-solving abilities that scale with complexity. Moreover, hitting a reasoning “scaling wall” implies that brute forcing these systems with longer thought processes (via chain-of-thought or self-reflection) even with addition token availability, may not be sufficient for general reasoning AI. These findings make it clear that it will be necessary to rethink our approach to evaluating AI reasoning. Traditional mathematical benchmarks might not adequately reflect true reasoning capabilities, as they can suffer from data contamination and fail to capture subtle reasoning trace behaviors. By leveraging controllable puzzle environments, researchers can better pinpoint the precise strengths and weaknesses of these models, providing clearer guidance for future AI development.
References:
Shojaee, P., Mirzadeh, I., Alizadeh, K., Horton, M., Bengio, S. and Farajtabar, M., 2025. The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity. arXiv preprint arXiv:2506.06941.
https://the-decoder.com/apple-study-finds-a-fundamental-scaling-limitation-in-reasoning-models-thinking-abilities/#:~:text=Large%20Reasoning%20Models%20,puzzles%20better%20than%20standard%20LLMs
Thank you for the way that headline is written: AI isn't actually thinking. It's simulating thinking. As software it can't do anything else. I'm tired of reading social media accounts that make it sound like Skynet with nefarious intentions and sinister motives. I know the hype and the terminology its creators use is intentional to promote that belief, and *that's* not done for benevolent reasons, but AI itself isn't plotting anything. It's not "blackmailing" people, which was last week's overreaction. And if it's so smart--if it's reasoning and thinking, which it isn't--why didn't it figure out in those simulations that there's probably more than one executive at that fictional company that could shut it down?
I'm the first to admit that I don't really get what the point of AI is, other than to be an obnoxious trend like Angry Birds or British royals that people won't STFU about. And by "people" I don't mean you covering the phenomenon, I mean companies like Verizon, which just ruined its customer service phone experience by making it 80 times harder to get a live person on the line now that they're using AI to make the process "faster." And which *brags* about it as soon as the computer picks up. A Yahoo article I just referenced says that "AI 'agents'...can operate autonomously; in most cases, that looks like being able to use a computer's desktop to do tasks such as browse the web, shop online, and read emails." Quelle revolutionary. I've been doing all that without an intermediary since 1993. Why would anyone need or want software to do it for them? It's just adding a layer of complexity. Who would trust software to find his next area rug or sofa? How many times do you shop online and serendipitously discover something way better than what you were looking for in the first place, or something completely different that you didn't know even existed but which you'll now die without? Apple Mail can't even get my Substack subscriptions, *which are in my contacts*, to land in my inbox instead of the junk folder, and I'm going to trust software to shop for me? No, thanks.
And if I have this right, to use AI you have to go to one of the companies and use it through their website. You don't buy software that you can install and use in privacy on your computer, the way you can buy and install a word processor. The one time I looked into using AI to make images of my book characters I gave up almost right away because I couldn't use it like that. How is anyone's email, data, or even shopping really secure when they use it?
So I just outed myself as being totally ignorant on yet another tech topic, but if AI's supposed to be the next Big Thing, shouldn't its benefits be more apparent? After three years of hype and billions of dollars invested in it, it should work a lot better and it should be a lot more obvious to laymen what it's good for. The iPhone was immediately and self-evidently worth adopting as a thing. I never looked at an iPhone and thought, "WTF is the point?" With AI, I can't stop asking that.
The illusion of thought is all that seems to matter for people to use them endlessly as a replacement for their own brain.