


DALL·E 3 IS INCREDIBLE! ... and a little creepy
Exploring the Wonders and Peculiarities of OpenAI's Latest Image Generator


Last night, I received early access to DALL·E 3, OpenAI’s image generator. Let me tell you, it has blown my mind! I believe access is still only being granted on a rolling basis, so this may not yet be available for everyone (yet). If you have access, check it out. For those awaiting access, fear not! I’ll be sharing the results of my experiments, and you can decide whether it lives up to the hype. But first, a brief overview of AI image generators and their foundational technology.
A Brief Explanation of AI Image Generators
AI image generators are software that utilizes advanced algorithms to create images that are becoming increasingly difficult to distinguish from something captured by a camera or created by an artist. These technologies have evolved on various platforms over the past few years and adopted different methodologies. The current dominant players (e.g., Midjourney and Firefly) in the field predominantly use a process called ‘Stable Diffusion.’
But what exactly is Stable Diffusion?
Stable Diffusion, in the context of image generation, is like an artist who creates a picture by initially blurring it out and then meticulously bringing it back into focus. Imagine spilling ink into water, watching it spread and then somehow controlling it to form a specific image – that's somewhat how this technology works. It begins with a clear image, introduces a kind of 'noise' to blur it into obscurity, and then, through a series of calculated steps, gradually refines it back into a clear, detailed image (click here for greater technical depth). This technique enables the creation of realistic and high-quality images by navigating through a vast space of possible images, ensuring the final result closely aligns with real-world visuals and patterns.

{kind=link}
DALL·E 3 is a Different Breed of Image Generator
In contrast, DALL·E 3 takes a divergent path in the field of image generation. Instead of relying on a diffusion process, DALL·E leverages a variant of the GPT-3 language model, enabling it to understand and generate images based on textual descriptions and context. OpenAI claims that when a user provides a textual prompt, DALL·E interprets it and generates an image that not only visually represents the text but also maintains a contextual and creative coherence. This ability to comprehend and visualize textual prompts may be a significant step forward for DALL·E compared to AI image generators using stable diffusion (or so they claim).
Let’s take DALLE for a spin.
My Experiments With DALL·E 3
I started by testing DALL·E 3 by asking it to generate thumbnails for some of my previously published substack articles. To prompt it, I copied and pasted the article text into the DALL·E 3 chat window and asked for a representative thumbnail based on the article text. Here are some of the results and DALL·E’s explanations for the generated thumbnails.
Prompt Article: I. Overview and Introduction. This post introduces an article series discussing the existential risk of AI and the urgent need to enhance human intelligence.

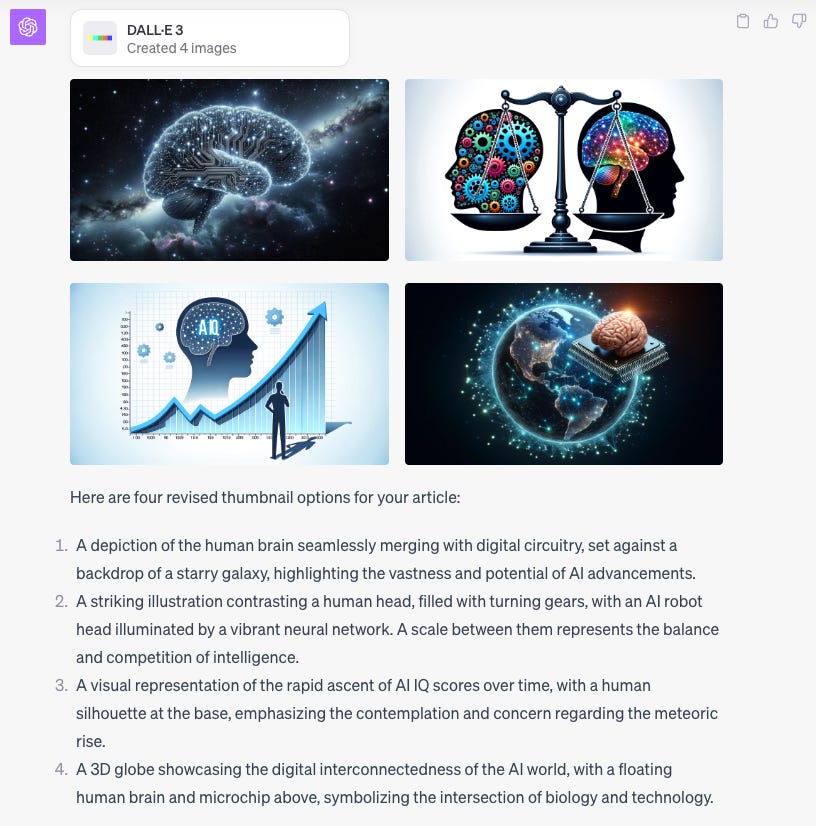
My mind was immediately blown. Not only are these all beautiful and interesting images, but it is clear that the AI understood the article's content. I won’t explain all of the images in depth, but I would like to highlight a few observations.
The AI understood the article’s primary topic as a conflict between biological and machine intelligence. It shows this by juxtaposing a brain and a computer chip on scales as if to measure them relative to each other.
The AI understands the concepts in the article are both global and existential. It attempts to illustrate this by using imagery of the globe and outer space.
This may be one of the most interesting parts: DALLE attempted to show the rapid increase in machine intelligence with a simulated graph or plot. While this plot was far from perfect (such as axis labeling errors), it still clearly communicates the idea behind increasing machine intelligence.
Prompt: IV. Reaching vs Expanding Biological Potential. For those who haven’t read this article, it explores various biological strategies to enhance human intelligence beyond it’s native potential.

Again, these are gorgeous images! I was particularly impressed by how DALLE derived prompts from the article that are both literally and metaphorically relevant.
Okay, now let’s change it up a bit.
Prompt: Create a hyper-realistic Halloween-themed image of a Dodo bird sitting inside a pumpkin.

Or how about something a bit more spooky.
Prompt: A hyper-realistic zombie Woolly Mammoth with rotting flesh.

Next, I asked DALLE if it could add motion to the image.

While it sadly cannot generate motion, I decided to try making a gif of a sequence of static images as suggested.

I took these images and uploaded them to a GIF generator.

How neat! Not only did DALLE give a great suggestion, but the resulting GIF was very cool.
Next, I asked DALLE to create a poster advertising itself (i.e., advertise DALLE, the AI image generator). As part of the prompt, I stated that I wanted the poster to be themed in a specific decade, e.g., 1970s to 2020s. I took the two best pictures for each decade to create the series below:
Again, these are absolutely cool and beautiful images! DALLE the software, is anthropomorphized as a helpful robot that goes from looking naive and cartoonish to increasingly cool and science fiction appearing. Further, the themes for each of these appear to be spot on for each decade. You can even see the Game Boy in the 1990s poster!
What if we ask DALLE to make posters for the next six decades (2030 - 2080)? This would essentially be asking DALLE to make predictions about the future. Let’s see what we get:

Alright, this feels like it took an uncomfortable turn… In the posters from the 1970s to the 2020s, the Robot representing DALL·E looks friendly, helpful, and a bit subservient. However, in the 2030s through 2080s posters, the robot representing DALL-E 3 looks increasingly imposing and domineering. In the final few decades, DALLE looks menacing to ‘Godlike’...
Is this a warning?
Conclusions on DALL·E 3:
DALL·E 3 has seemingly not only caught up but likely passed most (if not all) the Stable Diffusion-based AI image generators. It has incredible features like embedding text within images, albeit with spelling inaccuracies or just whole made-up words. It exhibits a robust ability to interpret text, extract concepts, and generate images that are literally and metaphorically driven. While it doesn’t seem to allow the generation of identical images with subtle variations, it can come fairly close. Overall, DALLE 3 is absolutely incredible, and it is only a matter of time until everyone begins to utilize this incredible tool.
I never used Dall-E, well I tried a few times way back, but it never amounted to anything usable. Seems V3 is a huge improvement! Going to give this a whirl. Appreciate the explanations, David. I always choose "short runtime" (fewer steps) because of credits. Still don't understand the Sampling Method differences, EULER, DPM, LMS, DPMPP_2PP (Default) etc... There are a lot of parameters and negative prompts and stuff where writing a good prompt is the biggest challenge and then being lucky and getting a good seed, at least with Stable Diffusion. Dall-E 3 seems to get rid of all that cryptic pre-work.
I wish I could zoom in to see the ads better! But from what I can see, you’re correct how the quality of fun and helpful changed to godlike in the futuristic ads.